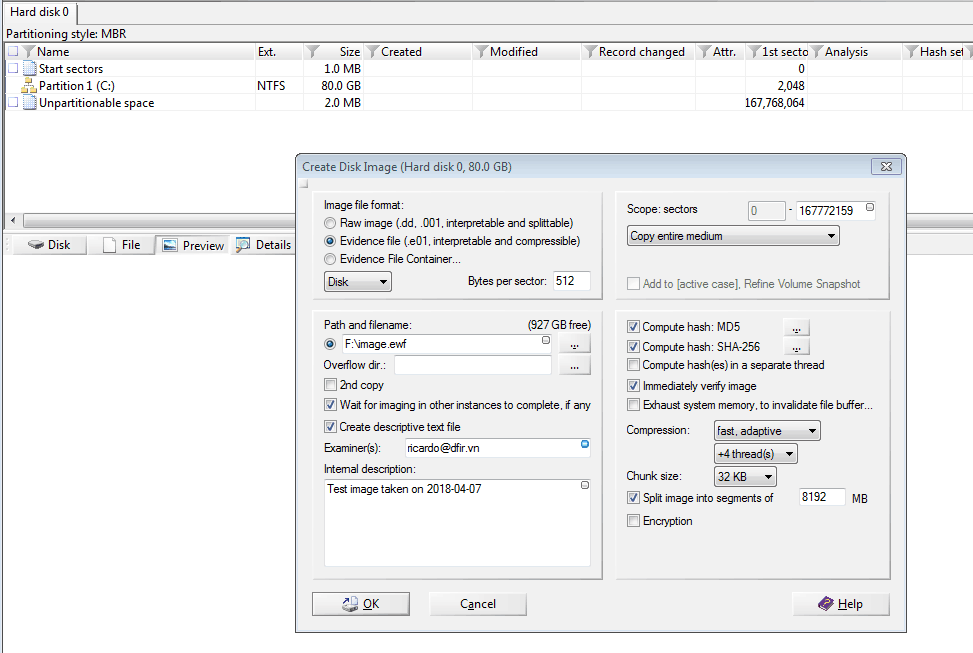
Autopsy is a digital forensics and graphical interface to The Sleuth Kit and other forensic tools (https://www.sleuthkit.org/autopsy/). The main function is the ability to ingest an disk raw image or evidence file, carve files out of it (including deleted files) and then index all records into an index (powered by Apache Solr) in order to allow the forensic investigator to perform searches. The tool also provides with a timeline management editor.
Introduction
Why Autopsy instead of the most common alternative (Encase Forensics or X-Ways Forensics)?
- For investigators in Vietnam (specially on internal investigation withing a company), the price point of Encase Forensics (~$3,500) or X-Ways Forensics (~$2000) can simply be too steep.
- On a forensic investigation, once capturing, ingesting and indexing is done, some “advanced” work is done via third party tools/modules (think mobile phone backups, PST file expansion, Skype database readers). This is the case for both Encase and Autopsy.
- Encase licensing is tied to the local hardware. Addition of new hard drives, more RAM onto an Encase system will require relicensing (of which you have 3 tries on a standard license) before Encase will stop working at all. You can not run multiple copies on Encase simultaneously. In large digital forensic ingestions (200GB+), indexing takes hours. Having multiple instances of a forensic package analyzing separate images can be essential for a forensics team operating on a time critical environment. X-Ways forensics has a flexible BYOD licensing where the license is tied up to a removable drive (http://www.x-ways.net/BYOD.html).
- The Autopsy module set is growing steadily (https://wiki.sleuthkit.org/index.php?title=Autopsy_3rd_Party_Modules) being based on Java and Python. Their API is simple enough to use for investigators with a programming background (http://www.sleuthkit.org/autopsy/docs/api-docs/4.5.0/).
However Autopsy is only supported for Windows on the current version (that is the main OS used by their user base). The last version of Autopsy that officially supported multi-platform was version 2 (which was originally written in Perl – https://www.sleuthkit.org/autopsy/v2/). A full rewrite to Java was released in Autopsy 3. The current version at the time of writing (4.5) is based on Java and while multi-platform in design, most modules are Windows only.
Why would we want Autopsy on Linux, instead of taking the easy way out and running it on a Windows virtual machine?
- Evidence management. Linux is far more capable when imaging (acquiring) evidence (upcoming article). Images can be seamlessly mounted for a large variety of filesystems using loop devices. On NTFS filesystems, VSS copies can also be simultaneously mounted out of the same evidence file (built-in into X-Ways, requires a module on Encase).
- Performance. Autopsy image ingestion means populating a Solr index. This is computationally expensive and bound by the size of the available RAM on the device and, when that is exhausted, by the I/O speed of the storage device. Our experience tells us that Linux is slighly faster (more available RAM by default, higher I/O).
We are not starting from scratch here. There are available guides (if outdated) to install and run Autopsy 4 on Linux. The most complete one is by Petter Lopes at Pericia Computacional in Brazil (https://periciacomputacional.com/linux-install-autopsy/). But still requires a lot of tweaking to get right, hence this article.
Installation
Install your favourite Linux version. It has to support Java 8 and a full compile/build environment. In this example we are using Ubuntu Xenial LTS 16.04.3 , but any other Debian 8 based version would do. Update all the packages and reboot.
As root: # apt-get update && apt-get -y upgrade && apt-get -y dist-upgrade
Add Java 8 from the webupd8team ppa (https://launchpad.net/~webupd8team/+archive/ubuntu/java) (you will be prompted to accept Oracle’s binary license):
add-apt-repository ppa:webupd8team/java apt-get update apt-get install oracle-java8-installer oracle-java8-set-default
Make java 8 the default JRE and use it as JAVA_HOME, or solr-tomcat will not run.
export JAVA_HOME=”/usr/lib/jvm/java-8-oracle/” export JDK_HOME=”/usr/lib/jvm/java-8-oracle/” export JRE_HOME=”/usr/lib/jvm/java-8-oracle/jre/”
Get the prerequisite packages (and get a coffee, this is a 1.2GB download on our VM):
apt-get install ant autoconf automake autopoint autotools-dev build-essential byacc bzip2 debhelper fakeroot flex git git-svn gstreamer1.0 libafflib-dev libbz2-dev libcppunit-dev libfuse-dev libssl-dev libtool libz-dev pkg-config python3-all-dev python-all-dev python-dev software-properties-common solr-tomcat uuid-dev vim wget xauth zlib1g-dev
Now we need to get three git repositories (libewf, sleuthkit and autopsy). In this particular example, the working directory is /usr/src.
git clone https://github.com/libyal/libewf.git git clone https://github.com/sleuthkit/sleuthkit.git git clone https://github.com/sleuthkit/autopsy.git
We need to set the TSK_HOME variable to point to the Sleuthkit directory:
export TSK_HOME=/usr/src/sleuthkit
Then build libewf and install it within /usr/local/lib (default)
cd /usr/src/libewf ./synclibs.sh ./autogen.sh ./configure --enable-python make make install
Once libewf is compiled and installed, we need to compile Sleuthkit. We need to verify that the configure script for sleuthkit does return that libewf support is set to yes, otherwise something has gone wrong on the previous installation.
cd /usr/src/sleuthkit ./bootstrap ./configure --prefix=/usr/src/sleuthkit --with-libewf=/usr/local make make check make install
If compilation fails with (https://github.com/sleuthkit/sleuthkit/issues/642) just modify ewf.c
https://github.com/jarylc/dff-modules/commit/06c83df2b30ca597d32777f3ce6745a2b83b5f79
NOTE: Fork all repositories
Once installed we need to compiled the postgresql bundings for sleuthkit. This way Autopsy will use postgres when available.
cd bindings/java ant dist-PostgreSQL cd dist ln -s sleuthkit-4.6.0.jar sleuthkit-postgresql-4.6.0.jar
Create the relevant postgrest database
Run Autopsy
cd /usr/src/autopsy ant clean ant build ant run
And at this point Autopsy should load and run, but the first run will download a lot of jar files from maven.org (second cup of coffee required here – unless you have a local artifactory server holding most of repo1.maven.org already). Once downloaded you will see the main screen coming up.
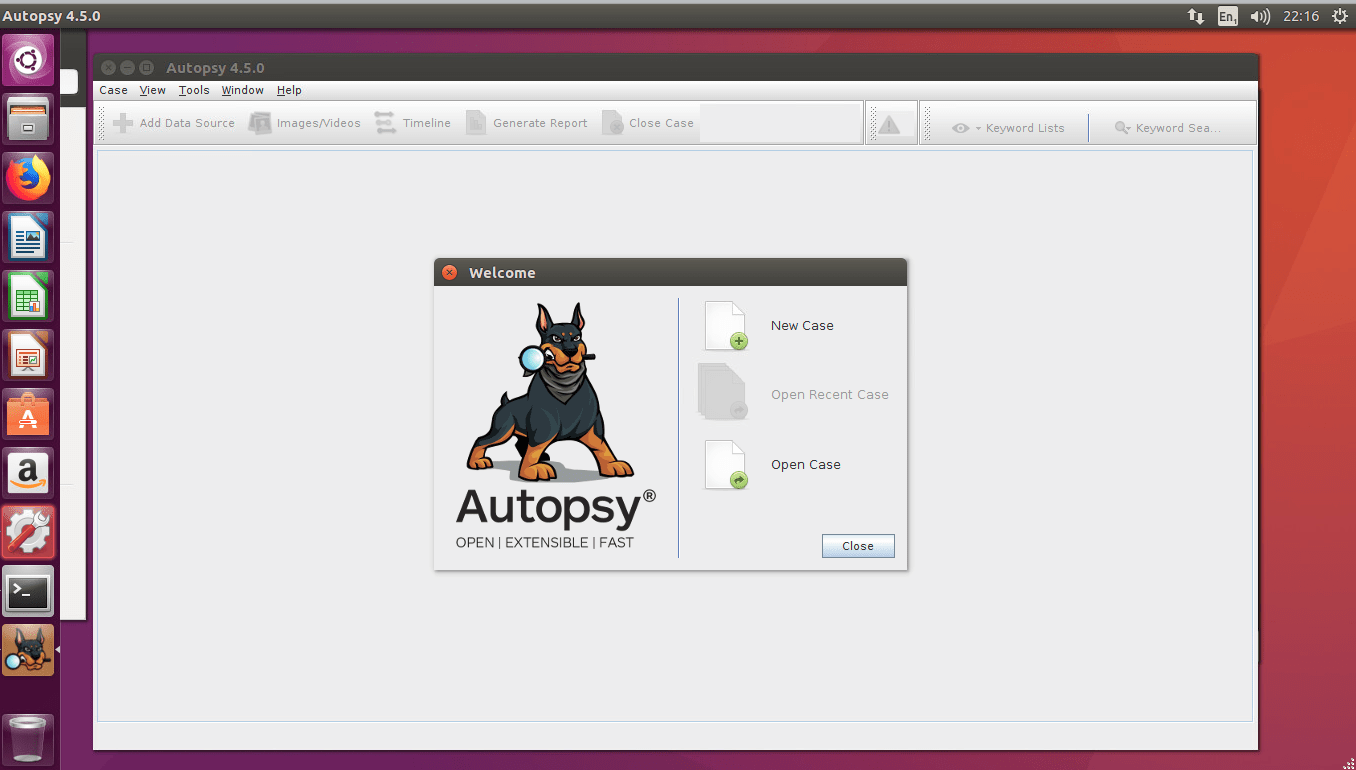
And you can create the first case..

And you could try loading some images from the NIST corpus (https://www.cfreds.nist.gov/data_leakage_case/data-leakage-case.html), which is a great resource. The example below runs Autopsy on two images:
- Raw DD image on https://www.cfreds.nist.gov/data_leakage_case/images/rm%232/cfreds_2015_data_leakage_rm%232.7z
- Encase EWF image on https://www.cfreds.nist.gov/data_leakage_case/images/rm%232/cfreds_2015_data_leakage_rm%232.E01

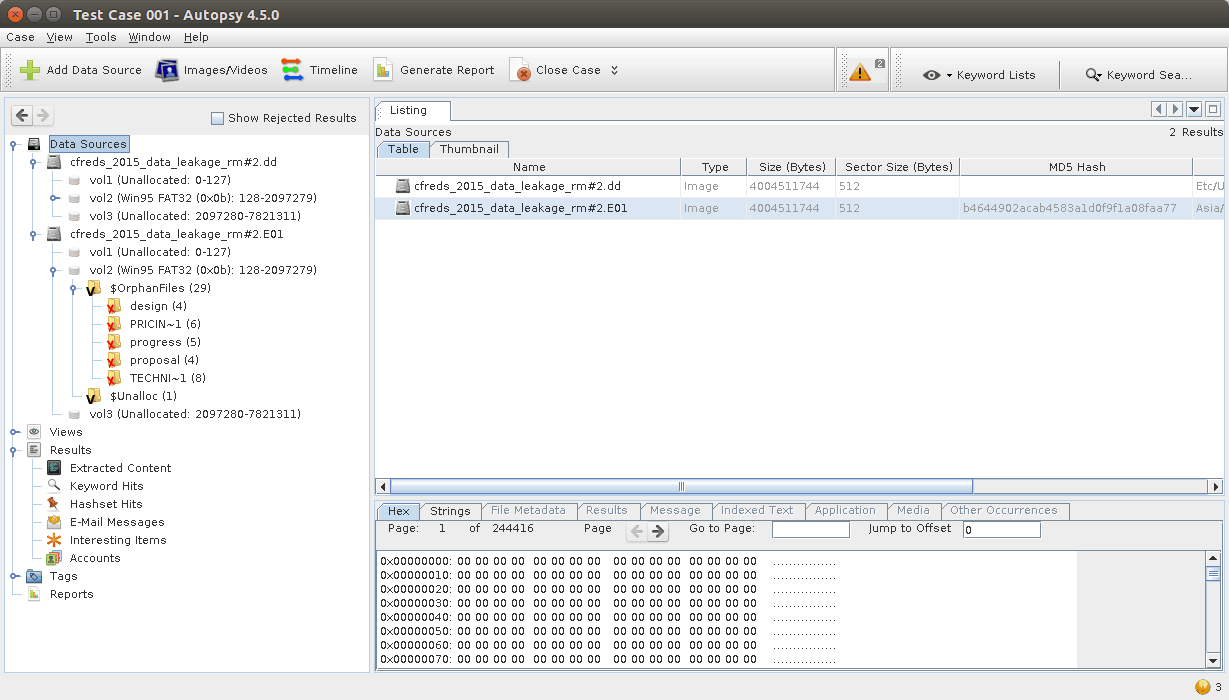
From there on, you have a working Autopsy system able to ingest images on multiple formats.
Follow this blog for more tips on digital forensics!
The DFIR VN lab team